Patterns
There are a few common design patterns throughout all paradigms of game development. These include the concept of loops, events, systems, and updates. A specific project might not use all of them, but any significant one will naturally make use of most, if not all of these patterns.
Systems
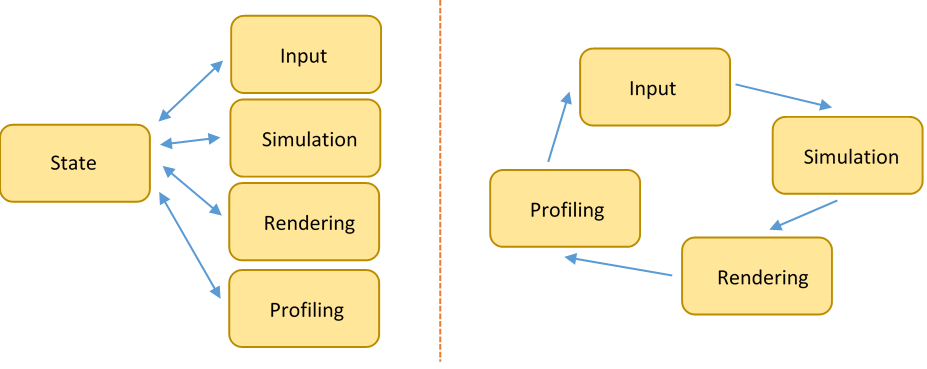
A common method of data abstraction in game development is breaking up what needs to happen each frame into mostly independent sub-systems. This often includes user input, simulation, rendering, and diagnostics. There are two main ways of doing this (and many paradigms of organization). First, there is a data and state oriented design. This is a more traditional design: a global "game state," containing all current information, is operated on and updated by each subsystem. This means that the systems primarily consist of logic. This is very simple to do in imperative languages like C. A more modern (but not necessarily better) approach is to make each system as modular as possible: instead of operating on a global state, a system contains the data collections it operates on. This is more straightforward in OOP-only languages like Java. As with most other design decisions, C++ can go either way.
Loops
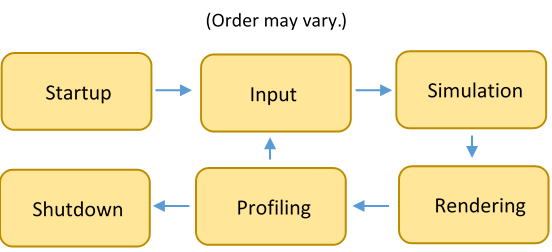
In the SDL lessons, I've touched on the concept of "game" or "program" loops. A program loop is simply the outermost loop that keeps the program running until it is ready to shut down. A game loop carries a little more specificity, consisting of a few general parts. Typically, one run-through of the game loop is considered one frame. Processes should be updated once, rendering should be done once, and the result should be swapped on the window once. Hence, a game loop includes calls to each sub-system of the game, including input, simulation, and rendering. That's really all that is necessary—even the most complicated games implement this general design at their core.
Events
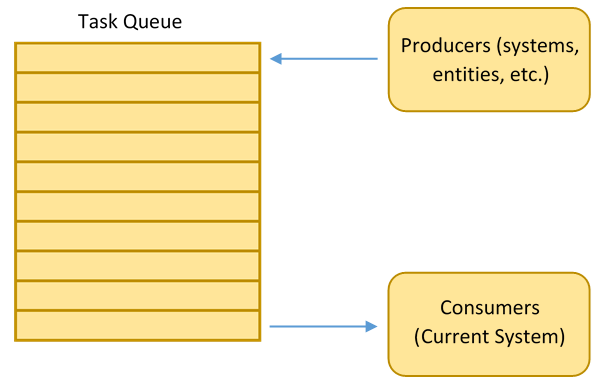
Event systems are a common and useful design with many applications. We've seen one used before—SDL's input system. However, event systems are not at all limited to input. For example, simulation (AI, physics, whatever) can be run in a similar way. When something changes or needs to be updated, an event is pushed to the event queue. Later, events are pulled off this queue to be processed.
The same design can be used whenever you have one or more producers and consumers. Producer code adds tasks to a queue. A task can be an event, a problem to solve, a process to update—really anything. Consumer code takes tasks out of the queue and resolves them by doing whatever task is required. This sort of setup is very common in multi-threaded programming (where multiple blocks of code may run concurrently).
For example, a task queue might be used to update entity AI. The producer code might go through all entities that need to be updated and push the tasks into the queue. Later (or on another thread), the consumer code can resolve these tasks and update the entities.
Updates
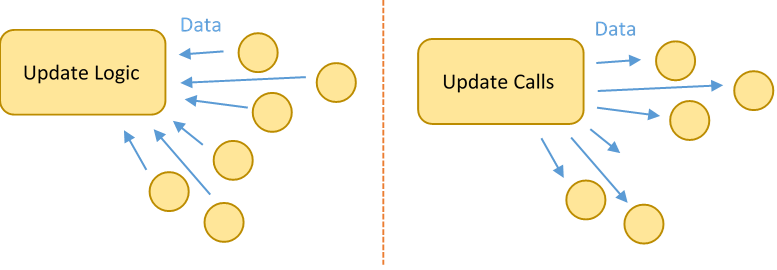
Some problems are better solved with update-based instead of event-based systems. An update system, instead of pushing tasks onto a queue, simply updates each 'thing' with a given time interval. This type of design is also useful for simulation (again AI, physics, whatever).
There are two common ways of doing this. I'll use entity simulation as an example (which we will cover in more depth later). First, you might have a simulation system that contains all simulation logic. This system goes through and updates each entity. In this case, the entity is simply a collection of data. Second, you might have the entities include their own specific simulation logic, and the simulation "system" simply calls each included "entity.update(time)" method.