Functions are Vectors
Conceptualizing functions as infinite-dimensional vectors lets us apply the tools of linear algebra to a vast landscape of new problems, from image and geometry processing to curve fitting and machine learning.
Prerequisites: introductory linear algebra, introductory calculus, introductory differential equations.
This article received an honorable mention in 3Blue1Brown’s Summer of Math Exposition 3!
Functions as Vectors
Vectors are often first introduced as lists of real numbers—i.e. the familiar notation we use for points, directions, and more.

You may recall that this representation is only one example of an abstract vector space. There are many other types of vectors, such as lists of complex numbers, graph cycles, and even magic squares.
However, all of these vector spaces have one thing in common: a finite number of dimensions. That is, each kind of vector can be represented as a collection of $$N$$ numbers, though the definition of “number” varies.
If any $$N$$-dimensional vector is essentially a length-$$N$$ list, we could also consider a vector to be a mapping from an index to a value.
What does this perspective hint at as we increase the number of dimensions?
Dimensions
In higher dimensions, vectors start to look more like functions!
Countably Infinite Indices
Of course, a finite-length vector only specifies a value at a limited number of indices. Could we instead define a vector that contains infinitely many values?
Writing down a vector representing a function on the natural numbers ($$\mathbb{N}$$)—or any other countably infinite domain—is straightforward: just extend the list indefinitely.

This vector could represent the function $$f(x) = x$$, where $$x \in \mathbb{N}$$.1
Uncountably Infinite Indices
Many interesting functions are defined on the real numbers ($$\mathbb{R}$$), so may not be representable as a countably infinite vector. Therefore, we will have to make a larger conceptual leap: not only will our set of indices be infinite, it will be uncountably infinite.
That means we can’t write down vectors as lists at all—it is impossible to assign an integer index to each element of an uncountable set. So, how can we write down a vector mapping a real index to a certain value?
Now, a vector really is just an arbitrary function:

Precisely defining how and why we can represent functions as infinite-dimensional vectors is the purview of functional analysis. In this post, we won’t attempt to prove our results in infinite dimensions: we will focus on building intuition via analogies to finite-dimensional linear algebra.
Vector Spaces
Formally, a vector space is defined by choosing a set of vectors $$\mathcal{V}$$, a scalar field $$\mathbb{F}$$, and a zero vector $$\mathbf{0}$$. The field $$\mathbb{F}$$ is often the real numbers ($$\mathbb{R}$$), complex numbers ($$\mathbb{C}$$), or a finite field such as the integers modulo a prime ($$\mathbb{Z}_p$$).
Additionally, we must specify how to add two vectors and how to multiply a vector by a scalar.
To describe a vector space, our definitions must entail several vector space axioms.
A Functional Vector Space
In the following sections, we’ll work with the vector space of real functions. To avoid ambiguity, square brackets are used to denote function application.
- The scalar field $$\mathbb{F}$$ is the real numbers $$\mathbb{R}$$.
- The set of vectors $$\mathcal{V}$$ contains functions from $$\mathbb{R}$$ to $$\mathbb{R}$$.2
- $$\mathbf{0}$$ is the zero function, i.e. $$\mathbf{0}[x] = 0$$.
Adding functions corresponds to applying the functions separately and summing the results.

This definition generalizes the typical element-wise addition rule—it’s like adding the two values at each index.
Multiplying a function by a scalar corresponds to applying the function and scaling the result.

This rule similarly generalizes element-wise multiplication—it’s like scaling the value at each index.
Proofs
Given these definitions, we can now prove all necessary vector space axioms. We will illustrate the analog of each property in $$\mathbb{R}^2$$, the familiar vector space of two-dimensional arrows.

Since real addition is commutative, this property follows directly from our definition of vector addition:

This property also follows from our definition of vector addition:

This one is easy:

Negation is defined as applying $$f$$ and negating the result: $$(-f)[x] = -f[x]$$. Clearly, $$-f$$ is also in $$\mathcal{V}$$.

Note that $$1$$ is specified by the choice of $$\mathbb{F}$$. In our case, it is simply the real number $$1$$.

This property follows from our definition of scalar multiplication:

Again using our definitions of vector addition and scalar multiplication:

Again using our definitions of vector addition and scalar multiplication:
Therefore, we’ve built a vector space of functions!3 It may not be immediately obvious why this result is useful, but bear with us through a few more definitions—we will spend the rest of this post exploring powerful techniques arising from this perspective.
A Standard Basis for Functions
Unless specified otherwise, vectors are written down with respect to the standard basis. In $$\mathbb{R}^2$$, the standard basis consists of the two coordinate axes.

Hence, vector notation is shorthand for a linear combination of the standard basis vectors.

Above, we represented functions as vectors by assuming each dimension of an infinite-length vector contains the function’s result for that index. This construction points to a natural generalization of the standard basis.
Just like the coordinate axes, each standard basis function contains a $$1$$ at one index and $$0$$ everywhere else. More precisely, for every $$\alpha \in \mathbb{R}$$:
Ideally, we could express an arbitrary function $$f$$ as a linear combination of these basis functions. However, there are uncountably many of them—and we can’t simply write down a sum over the reals. Still, considering their linear combination is illustrative:
If we evaluate this “sum” at $$x$$, we’ll find that all terms are zero—except $$\mathbf{e}_x$$, making the result $$f[x]$$.
Linear Operators
Now that we can manipulate functions as vectors, let’s start transferring the tools of linear algebra to the functional perspective.
One ubiquitous operation on finite-dimensional vectors is transforming them with matrices. A matrix $$\mathbf{A}$$ encodes a linear transformation, meaning multiplication preserves linear combinations.
Multiplying a vector by a matrix can be intuitively interpreted as defining a new set of coordinate axes from the matrix’s column vectors. The result is a linear combination of the columns:
When all vectors can be expressed as a linear combination of $$\mathbf{u}$$, $$\mathbf{v}$$, and $$\mathbf{w}$$, the columns form a basis for the underlying vector space. Here, the matrix $$\mathbf{A}$$ transforms a vector from the $$\mathbf{uvw}$$ basis into the standard basis.
Since functions are vectors, we could imagine transforming a function by a matrix. Such a matrix would be infinite-dimensional, so we will instead call it a linear operator and denote it with $$\mathcal{L}$$.
This visualization isn’t very accurate—we’re dealing with uncountably infinite-dimensional vectors, so we can’t actually write out an operator in matrix form. Nonetheless, the structure is suggestive: each “column” of the operator describes a new basis function for our functional vector space. Just like we saw with finite-dimensional vectors, $$\mathcal{L}$$ represents a change of basis.
Differentiation
So, what’s an example of a linear operator on functions? You might recall that differentiation is linear:
It’s hard to visualize differentiation on general functions, but it’s feasible for the subspace of polynomials, $$\mathcal{P}$$. Let’s take a slight detour to examine this smaller space of functions.
We typically write down polynomials as a sequence of powers, i.e. $$1, x, x^2, x^3$$, etc. All polynomials are linear combinations of the functions $$\mathbf{e}_i[x] = x^i$$, so they constitute a countably infinite basis for $$\mathcal{P}$$.4
This basis provides a convenient vector notation:
Since differentiation is linear, we’re able to apply the rule $$\frac{\partial}{\partial x} x^n = nx^{n-1}$$ to each term.
We’ve performed a linear transformation on the coefficients, so we can represent differentiation as a matrix!
Each column of the differentiation operator is itself a polynomial, so this matrix represents a change of basis.
As we can see, the differentiation operator simply maps each basis function to its derivative.
This result also applies to the larger space of analytic real functions, which includes polynomials, exponential functions, trigonometric functions, logarithms, and other familiar names. By definition, an analytic function can be expressed as a Taylor series about $$0$$:
Which is a linear combination of our polynomial basis functions. That means a Taylor expansion is essentially a change of basis into the sequence of powers, where our differentiation operator is quite simple.5
Diagonalization
Matrix decompositions are arguably the crowning achievement of linear algebra. To get started, let’s review what diagonalization means for a $$3\times3$$ real matrix $$\mathbf{A}$$.
Eigenvectors
A vector $$\mathbf{u}$$ is an eigenvector of the matrix $$\mathbf{A}$$ when the following condition holds:

The eigenvalue $$\lambda$$ may be computed by solving the characteristic polynomial of $$\mathbf{A}$$. Eigenvalues may be real or complex.
The matrix $$\mathbf{A}$$ is diagonalizable when it admits three linearly independent eigenvectors, each with a corresponding real eigenvalue. This set of eigenvectors constitutes an eigenbasis for the underlying vector space, indicating that we can express any vector $$\mathbf{x}$$ via their linear combination.

To multiply $$\mathbf{x}$$ by $$\mathbf{A}$$, we just have to scale each component by its corresponding eigenvalue.

Finally, re-combining the eigenvectors expresses the result in the standard basis.

Intuitively, we’ve shown that multiplying by $$\mathbf{A}$$ is equivalent to a change of basis, a scaling, and a change back. That means we can write $$\mathbf{A}$$ as the product of an invertible matrix $$\mathbf{U}$$ and a diagonal matrix $$\mathbf{\Lambda}$$.
Note that $$\mathbf{U}$$ is invertible because its columns (the eigenvectors) form a basis for $$\mathbb{R}^3$$. When multiplying by $$\mathbf{x}$$, $$\mathbf{U}^{-1}$$ converts $$\mathbf{x}$$ to the eigenbasis, $$\mathbf{\Lambda}$$ scales by the corresponding eigenvalues, and $$\mathbf{U}$$ takes us back to the standard basis.
In the presence of complex eigenvalues, $$\mathbf{A}$$ may still be diagonalizable if we allow $$\mathbf{U}$$ and $$\mathbf{\Lambda}$$ to include complex entires. In this case, the decomposition as a whole still maps real vectors to real vectors, but the intermediate values become complex.
Eigenfunctions
So, what does diagonalization mean in a vector space of functions? Given a linear operator $$\mathcal{L}$$, you might imagine a corresponding definition for eigenfunctions:
The scalar $$\psi$$ is again known as an eigenvalue. Since $$\mathcal{L}$$ is infinite-dimensional, it doesn’t have a characteristic polynomial—there’s not a straightforward method for computing $$\psi$$.
Nevertheless, let’s attempt to diagonalize differentiation on analytic functions. The first step is to find the eigenfunctions. Start by applying the above condition to our differentiation operator in the power basis:
This system of equations implies that all coefficients are determined solely by our choice of constants $$p_0$$ and $$\psi$$. We can explicitly write down their relationship as $$p_i = \frac{\psi^i}{i!}p_0$$.
Now, let’s see what this class of polynomials actually looks like.
Differentiation shows that this function is, in fact, an eigenfunction for the eigenvalue $$\psi$$.
With a bit of algebraic manipulation, the definition of $$e^{x}$$ pops out:
Therefore, functions of the form $$p_0e^{\psi x}$$ are eigenfunctions for the eigenvalue $$\psi$$, including when $$\psi=0$$.
Diagonalizing Differentiation
We’ve found the eigenfunctions of the derivative operator, but can we diagonalize it? Ideally, we would express differentiation as the combination of an invertible operator $$\mathcal{L}$$ and a diagonal operator $$\mathcal{D}$$.
Diagonalization is only possible when our eigenfunctions form a basis. This would be true if all analytic functions are expressible as a linear combination of exponentials. However…
Differentiating both sides:
Since $$e^{\psi_n x}$$ and $$e^{\psi_m x}$$ are linearly independent when $$n\neq m$$, the final equation implies that all $$\alpha = 0$$, except possibly the $$\alpha_\xi$$ corresponding to $$\psi_\xi = 0$$. Therefore:
That’s a contradiction—the linear combination representing $$f[x] = x$$ does not exist.
A similar argument shows that we can’t represent any non-constant function whose $$n$$th derivative is zero, nor periodic functions like sine and cosine.
Real exponentials don’t constitute a basis, so we cannot construct an invertible $$\mathcal{L}$$.
The Laplace Transform
We previously mentioned that more matrices can be diagonalized if we allow the decomposition to contain complex numbers. Analogously, more linear operators are diagonalizable in the larger vector space of functions from $$\mathbb{R}$$ to $$\mathbb{C}$$.
Differentiation works the same way in this space; we’ll still find that its eigenfunctions are exponential.
However, the new eigenfunctions have complex eigenvalues, so we still can’t diagonalize. We’ll need to consider the still larger space of functions from $$\mathbb{C}$$ to $$\mathbb{C}$$.
In this space, differentiation can be diagonalized via the Laplace transform. Although useful for solving differential equations, the Laplace transform is non-trivial to invert, so we won’t discuss it further. In the following sections, we’ll delve into an operator that can be easily diagonalized in $$\mathbb{R}\mapsto\mathbb{C}$$: the Laplacian.
Inner Product Spaces
Before we get to the spectral theorem, we’ll need to understand one more topic: inner products. You’re likely already familiar with one example of an inner product—the Euclidean dot product.
An inner product describes how to measure a vector along another vector. For example, $$\mathbf{u}\cdot\mathbf{v}$$ is proportional to the length of the projection of $$\mathbf{u}$$ onto $$\mathbf{v}$$.

With a bit of trigonometry, we can show that the dot product is equivalent to multiplying the vectors’ lengths with the cosine of their angle. This relationship suggests that the product of a vector with itself produces the square of its length.
Similarly, when two vectors form a right angle (are orthogonal), their dot product is zero.

Of course, the Euclidean dot product is only one example of an inner product. In more general spaces, the inner product is denoted using angle brackets, such as $$ \langle \mathbf{u}, \mathbf{v} \rangle $$.
- The length (also known as the norm) of a vector is defined as $$|\mathbf{u}| = \sqrt{\langle \mathbf{u}, \mathbf{u} \rangle}$$.
- Two vectors are orthogonal if their inner product is zero: $$\ \mathbf{u} \perp \mathbf{v}\ \iff\ \langle \mathbf{u}, \mathbf{v} \rangle = 0 $$.
A vector space augmented with an inner product is known as an inner product space.
A Functional Inner Product
We can’t directly apply the Euclidean dot product to our space of real functions, but its $$N$$-dimensional generalization is suggestive.
Given countable indices, we simply match up the values, multiply them, and add the results. When indices are uncountable, we can convert the discrete sum to its continuous analog: an integral!
When $$f$$ and $$g$$ are similar, multiplying them produces a larger function; when they’re different, they cancel out. Integration measures their product over some domain to produce a scalar result.


Of course, not all functions can be integrated. Our inner product space will only contain functions that are square integrable over the domain $$[a, b]$$, which may be $$[-\infty, \infty]$$. Luckily, the important properties of our inner product do not depend on the choice of integration domain.
Proofs
Below, we’ll briefly cover functions from $$\mathbb{R}$$ to $$\mathbb{C}$$. In this space, our intuitive notion of similarity still applies, but we’ll use a slightly more general inner product:
Where $$\overline{x}$$ denotes conjugation, i.e. $$ \overline{a + bi} = a - bi $$.
Like other vector space operations, an inner product must satisfy several axioms:
Conjugation may be taken outside the integral, making this one easy:
Note that we require conjugate symmetry because it implies $$\langle\mathbf{u}, \mathbf{u}\rangle = \overline{\langle\mathbf{u}, \mathbf{u}\rangle}$$, i.e. the inner product of a vector with itself is real.
The proof follows from linearity of integration, as well as our vector space axioms:
Given conjugate symmetry, an inner product is also antilinear in the second argument.
By conjugate symmetry, we know $$\langle f, f \rangle$$ is real, so we can compare it with zero.
However, rigorously proving this result requires measure-theoretic concepts beyond the scope of this post.
In brief, we redefine $$\mathbf{0}$$ not as specifically $$\mathbf{0}[x] = 0$$, but as an equivalence class of functions that are zero “almost everywhere.”
If $$f$$ is zero almost everywhere, it is only non-zero on a set of measure zero, and therefore integrates to zero.
After partitioning our set of functions into equivalence classes, all non-zero functions square-integrate to a positive value. This implies that every function has a real norm, $$\sqrt{\langle f, f \rangle}$$.
Along with the definition $$|f| = \sqrt{\langle f, f \rangle}$$, these properties entail a variety of important results, including the Cauchy–Schwarz and triangle inequalities.
The Spectral Theorem
Diagonalization is already a powerful technique, but we’re building up to an even more important result regarding orthonormal eigenbases. In an inner product space, an orthonormal basis must satisfy two conditions: each vector is unit length, and all vectors are mutually orthogonal.

A matrix consisting of orthonormal columns is known as an orthogonal matrix. Orthogonal matrices represent rotations of the standard basis.
In an inner product space, matrix-vector multiplication computes the inner product of the vector with each row of the matrix. Something interesting happens when we multiply an orthogonal matrix $$\mathbf{U}$$ by its transpose:
Since $$\mathbf{U}^T\mathbf{U} = \mathcal{I}$$ (and $$\mathbf{U}\mathbf{U}^T = \mathcal{I}$$), we’ve found that the transpose of $$\mathbf{U}$$ is equal to its inverse.
When diagonalizing $$\mathbf{A}$$, we used $$\mathbf{U}$$ to transform vectors from our eigenbasis to the standard basis. Conversely, its inverse transformed vectors from the standard basis to our eigenbasis. If $$\mathbf{U}$$ happens to be orthogonal, transforming a vector $$\mathbf{x}$$ into the eigenbasis is equivalent to projecting $$\mathbf{x}$$ onto each eigenvector.

Additionally, the diagonalization of $$\mathbf{A}$$ becomes quite simple:
Given an orthogonal diagonalization of $$\mathbf{A}$$, we can deduce that $$\mathbf{A}$$ must be symmetric, i.e. $$\mathbf{A} = \mathbf{A}^T$$.
The spectral theorem states that the converse is also true: $$\mathbf{A}$$ is symmetric if and only if it admits an orthonormal eigenbasis with real eigenvalues. Proving this result is somewhat involved in finite dimensions and very involved in infinite dimensions, so we won’t reproduce the proofs here.
Self-Adjoint Operators
We can generalize the spectral theorem to our space of functions, where it states that a self-adjoint operator admits an orthonormal eigenbasis with real eigenvalues.6
Denoted as $$\mathbf{A}^{\hspace{-0.1em}\star\hspace{0.1em}}$$, the adjoint of an operator $$\mathbf{A}$$ is defined by the following relationship.
When $$\mathbf{A} = \mathbf{A}^\star$$, we say that $$\mathbf{A}$$ is self-adjoint.
The adjoint can be thought of as a generalized transpose—but it’s not obvious what that means in infinite dimensions. We will simply use our functional inner product to determine whether an operator is self-adjoint.
The Laplace Operator
Review: Solving the heat equation | DE3.
Earlier, we weren’t able to diagonalize (real) differentiation, so it must not be self-adjoint. Therefore, we will explore another fundamental operator, the Laplacian.
There are many equivalent definitions of the Laplacian, but in our space of one-dimensional functions, it’s just the second derivative. We will hence restrict our domain to twice-differentiable functions.
We may compute $$\Delta^\star$$ using two integrations by parts:
In the final step, we assume that $$(f^\prime[x]g[x] - f[x]g^{\prime}[x])\big|_a^b = 0$$, which is not true in general. To make our conclusion valid, we will constrain our domain to only include functions satisfying this boundary condition. Specifically, we will only consider periodic functions with period $$b-a$$. These functions have the same value and derivative at $$a$$ and $$b$$, so the additional term vanishes.
For simplicity, we will also assume our domain to be $$[0,1]$$. For example:
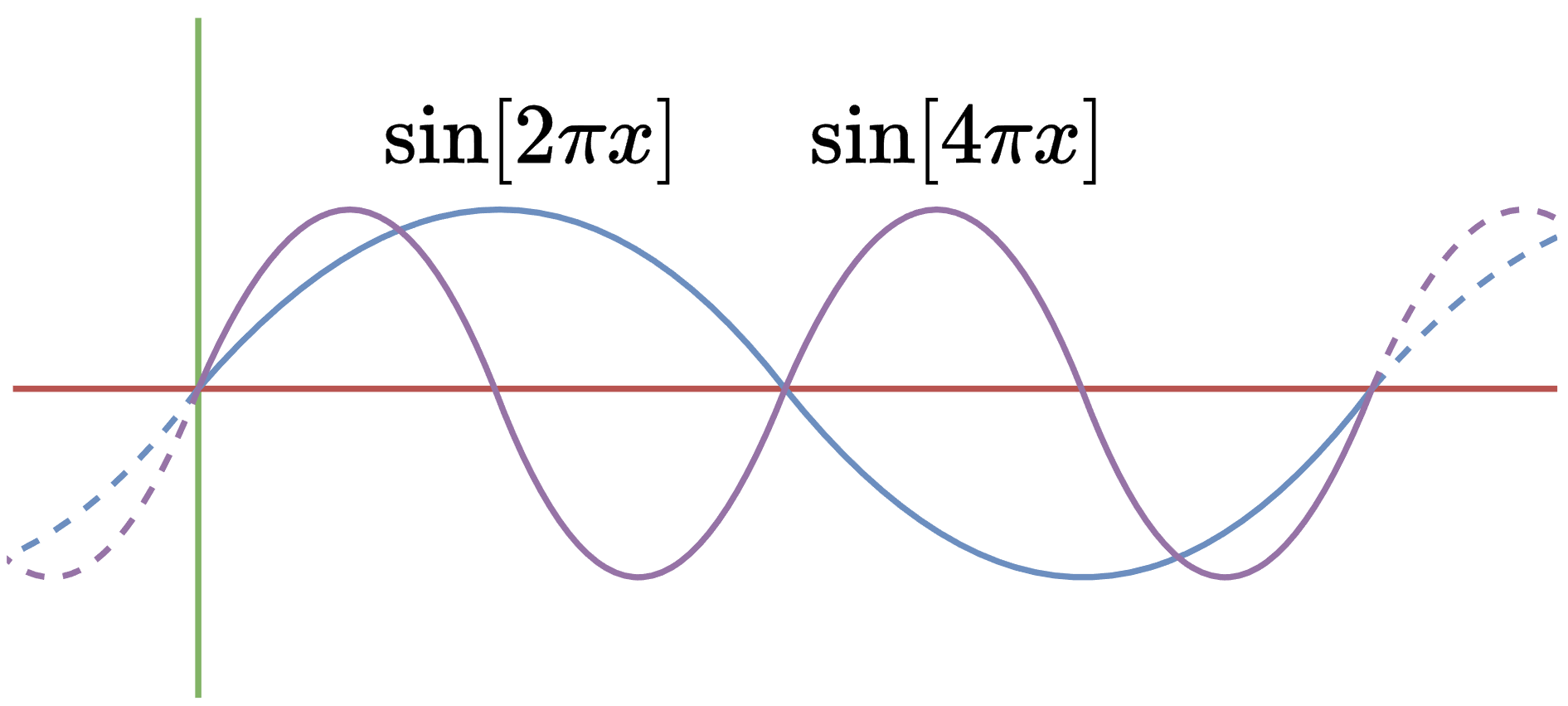
Therefore, the Laplacian is self-adjoint…almost. Technically, we’ve shown that the Laplacian is symmetric, not that $$\Delta = \Delta^\star$$. This is a subtle point, and it’s possible to prove self-adjointness, so we will omit this detail.
Laplacian Eigenfunctions
Applying the spectral theorem tells us that the Laplacian admits an orthonormal eigenbasis. Let’s find it.7
Since the Laplacian is simply the second derivative, real exponentials would still be eigenfunctions—but they’re not periodic, so we’ll have to exclude them.
Luckily, a new class of periodic eigenfunctions appears:
If we allow our diagonalization to introduce complex numbers, we can also consider functions from $$\mathbb{R}$$ to $$\mathbb{C}$$ . Here, purely complex exponentials are eigenfunctions with real eigenvalues.
Using Euler’s formula, we can see that these two perspectives are equivalent: they both introduce $$\sin$$ and $$\cos$$ as eigenfunctions. Either path can lead to our final result, but we’ll stick with the more compact complex case.
We also need to constrain the set of eigenfunctions to be periodic on $$[0,1]$$. As suggested above, we can pick out the eigenvalues that are an integer multiple of $$2\pi$$.
Our set of eigenfunctions is therefore $$e^{2\pi \xi i x}$$ for all integers $$\xi$$.
Diagonalizing the Laplacian
Now that we’ve found suitable eigenfunctions, we can construct an orthonormal basis.
Our collection of eigenfunctions is linearly independent, as each one corresponds to a distinct eigenvalue. Next, we can check for orthogonality and unit magnitude:
Note that the final step is valid because $$\xi_1-\xi_2$$ is a non-zero integer.
This result also applies to any domain $$[a,b]$$, given functions periodic on $$[a,b]$$.
It’s possible to further generalize to $$[-\infty,\infty]$$, but doing so requires a weighted inner product.
With the addition of a constant factor $$\frac{1}{b-a}$$, this result generalizes to any $$[a,b]$$.
It’s possible to further generalize to $$[-\infty,\infty]$$, but doing so requires a weighted inner product.
The final step is to show that all functions in our domain can be represented by a linear combination of eigenfunctions. To do so, we will find an invertible operator $$\mathcal{L}$$ representing the proper change of basis.
Critically, since our eigenbasis is orthonormal, we can intuitively consider the inverse of $$\mathcal{L}$$ to be its transpose.
This visualization suggests that $$\mathcal{L}^Tf$$ computes the inner product of $$f$$ with each eigenvector.
Which is highly reminiscent of the finite-dimensional case, where we projected onto each eigenvector of an orthogonal eigenbasis.
This insight allows us to write down the product $$\mathcal{L}^Tf$$ as an integer function $$\hat{f}[\xi]$$. Note that the complex inner product conjugates the second argument, so the exponent is negated.
Conversely, $$\mathcal{L}$$ converts $$\hat{f}$$ back to the standard basis. It simply creates a linear combination of eigenfunctions.
These operators are, in fact, inverses of each other, but a rigorous proof is beyond the scope of this post. Therefore, we’ve diagonalized the Laplacian:
Although $$\mathcal{L}^T$$ transforms our real-valued function into a complex-valued function, $$\Delta$$ as a whole still maps real functions to real functions. Next, we’ll see how $$\mathcal{L}^T$$ is itself an incredibly useful transformation.
Applications
In this section, we’ll explore several applications in signal processing, each of which arises from diagonalizing the Laplacian on a new domain.
Fourier Series
If you’re familiar with Fourier methods, you likely noticed that $$\hat{f}$$ encodes the Fourier series of $$f$$. That’s because a Fourier transform is a change of basis into the Laplacian eigenbasis!
This basis consists of waves, which makes $$\hat{f}$$ a particularly interesting representation for $$f$$. For example, consider evaluating $$\hat{f}[1]$$:
This integral measures how much of $$f$$ is represented by waves of frequency (positive) 1. Naturally, $$\hat{f}[\xi]$$ computes the same quantity for any integer frequency $$\xi$$.
$$\xi = 1$$
Therefore, we say that $$\hat{f}$$ expresses our function in the frequency domain. To illustrate this point, we’ll use a Fourier series to decompose a piecewise linear function into a collection of waves.8 Since our new basis is orthonormal, the transform is easy to invert by re-combining the waves.
Here, the $$\color{#9673A6}\text{purple}$$ curve is $$f$$; the $$\color{#D79B00}\text{orange}$$ curve is a reconstruction of $$f$$ from the first $$N$$ coefficients of $$\hat{f}$$. Try varying the number of coefficients and moving the $$\color{#9673A6}\text{purple}$$ dots to effect the results.
$$N = 3$$
Additionally, explore the individual basis functions making up our result:
| \[\hat{f}[0]\] | \[\hat{f}[1]e^{2\pi i x}\] | \[\hat{f}[2]e^{4\pi i x}\] | \[\hat{f}[3]e^{6\pi i x}\] |
Many interesting operations become easy to compute in the frequency domain. For example, by simply dropping Fourier coefficients beyond a certain threshold, we can reconstruct a smoothed version of our function. This technique is known as a low-pass filter—try it out above.
Image Compression
Computationally, Fourier series are especially useful for compression. Encoding a function $$f$$ in the standard basis takes a lot of space, since we store a separate result for each input. If we instead express $$f$$ in the Fourier basis, we only need to store a few coefficients—we’ll be able to approximately reconstruct $$f$$ by re-combining the corresponding basis functions.
So far, we’ve only defined a Fourier transform for functions on $$\mathbb{R}$$. Luckily, the transform arose via diagonalizing the Laplacian, and the Laplacian is not limited to one-dimensional functions. In fact, wherever we can define a Laplacian, we can find a corresponding Fourier transform.9
For example, in two dimensions, the Laplacian becomes a sum of second derivatives.
For the domain $$[0,1]\times[0,1]$$, we’ll find a familiar set of periodic eigenfunctions.
Where $$n$$ and $$m$$ are both integers. Let’s see what these basis functions look like:
$$n = 3$$
$$m = 3$$
Just like the 1D case, the corresponding Fourier transform is a change of basis into the Laplacian’s orthonormal eigenbasis. Above, we decomposed a 1D function into a collection of 1D waves—here, we equivalently decompose a 2D image into a collection of 2D waves.
$$N = 3$$
A variant of the 2D Fourier transform is at the core of many image compression algorithms, including JPEG.
Spherical Harmonics
Computer graphics is often concerned with functions on the unit sphere, so let’s see if we can find a corresponding Fourier transform. In spherical coordinates, the Laplacian can be defined as follows:
We won’t go through the full derivation, but this Laplacian admits an orthornormal eigenbasis known as the spherical harmonics.10
Where $$Y_\ell^m$$ is the spherical harmonic of degree $$\ell \ge 0$$ and order $$m \in [-\ell,\ell]$$. Note that $$N_\ell^m$$ is a constant and $$P_\ell^m$$ are the associated Legendre polynomials.11
$$\ell = 0$$
$$m = 0$$
As above, we define the spherical Fourier transform as a change of basis into the spherical harmonics. In game engines, this transform is often used to compress diffuse environment maps (i.e. spherical images) and global illumination probes.
$$N = 3$$
You might also recognize spherical harmonics as electron orbitals—quantum mechanics is primarily concerned with the eigenfunctions of linear operators.
Geometry Processing
Representing functions as vectors underlies many modern algorithms—image compression is only one example. In fact, because computers can do linear algebra so efficiently, applying linear-algebraic techniques to functions produces a powerful new computational paradigm.
The nascent field of discrete differential geometry uses this perspective to build algorithms for three-dimensional geometry processing. In computer graphics, functions on meshes often represent textures, unwrappings, displacements, or simulation parameters. DDG gives us a way to faithfully encode such functions as vectors: for example, by associating a value with each vertex of the mesh.
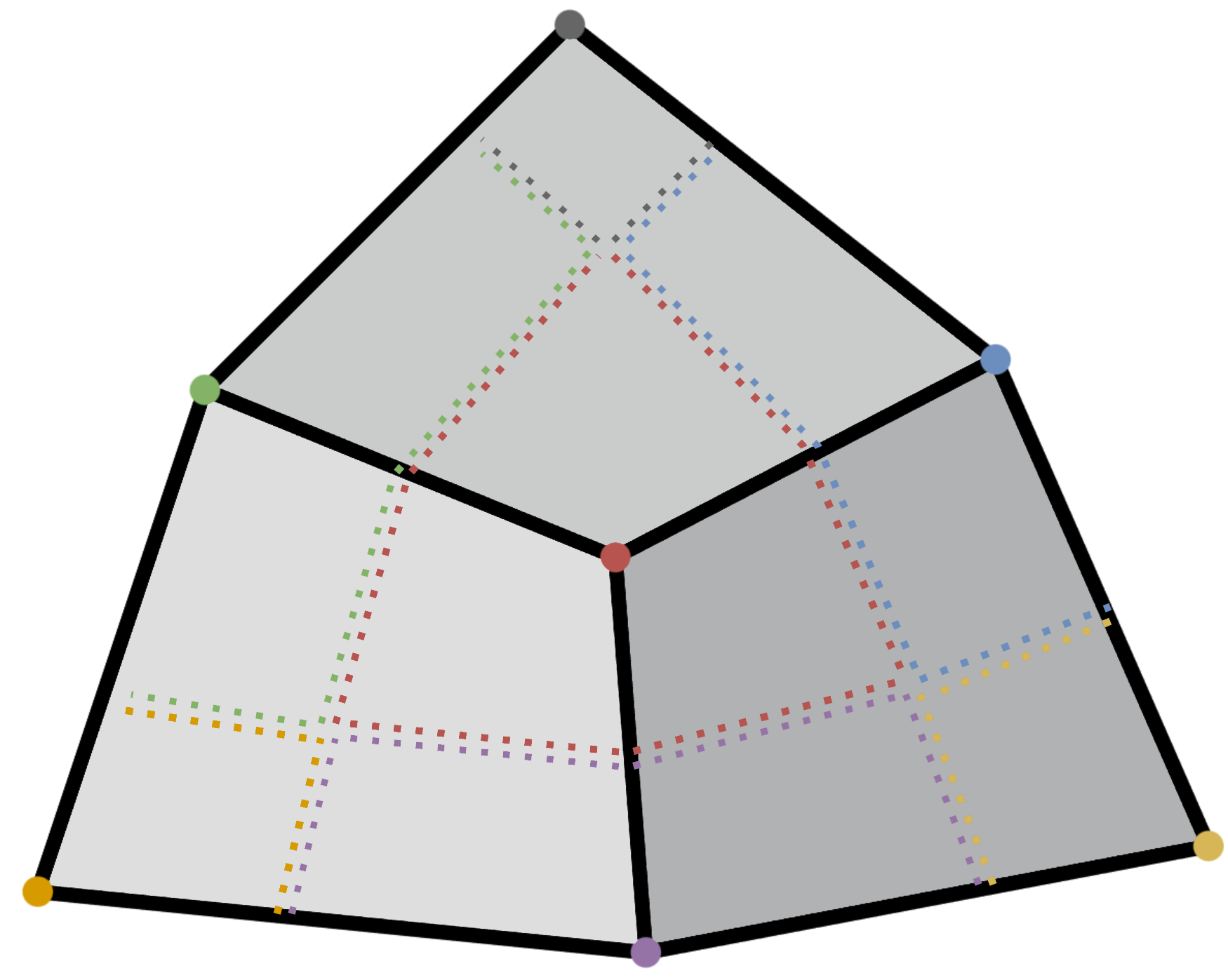
One particularly relevant result is a Laplace operator for meshes. A mesh Laplacian is a finite-dimensional matrix, so we can use numerical linear algebra to find its eigenfunctions.
As with the continuous case, these functions generalize sine and cosine to a new domain. Here, we visualize the real and complex parts of each eigenfunction, where the two colors indicate positive vs. negative regions.
$$4\text{th Eigenfunction}$$
At this point, the implications might be obvious—this eigenbasis is useful for transforming and compressing functions on the mesh. In fact, by interpreting the vertices’ positions as a function, we can even smooth or sharpen the geometry itself.
Further Reading
There’s far more to signal and geometry processing than we can cover here, let alone the many other applications in engineering, physics, and computer science. We will conclude with an (incomplete, biased) list of topics for further exploration. See if you can follow the functions-are-vectors thread throughout:
- Geometry: Distances, Parallel Transport, Flattening, Non-manifold Meshes, and Polygonal Meshes
- Simulation: the Finite Element Method, Monte Carlo PDEs, Minimal Surfaces, and Fluid Cohomology
- Light Transport: Radiosity, Operator Formulation (Ch.4), Low-Rank Approximation, and Inverse Rendering
- Machine Learning: DiffusionNet, MeshCNN, Kinematics, Fourier Features, and Inverse Geometry
- Splines: C2 Interpolation, Quadratic Approximation, and Simplification
Thanks to Joanna, Hesper Yin, and Fan Pu Zeng for providing feedback on this post.
Footnotes
We shouldn’t assume all countably infinite-dimensional vectors represent functions on the natural numbers. Later on, we’ll discuss the space of real polynomial functions, which also has countably infinite dimensionality. ↩︎
If you’re alarmed by the fact that the set of all real functions does not form a Hilbert space, you’re probably not in the target audience of this post. Don’t worry, we will later move on to $$L^2(\mathbb{R})$$ and $$L^2(\mathbb{R},\mathbb{C})$$. ↩︎
If you’re paying close attention, you might notice that none of these proofs depended on the fact that the domain of our functions is the real numbers. In fact, the only necessary assumption is that our functions return elements of a field, allowing us to apply commutativity, associativity, etc. to the outputs.
Therefore, we can define a vector space over the set of functions that map any fixed set $$\mathcal{S}$$ to a field $$\mathbb{F}$$. This result illustrates why we could intuitively equate finite-dimensional vectors with mappings from index to value. For example, consider $$\mathcal{S} = \{1,2,3\}$$:
\[\begin{align*} f_{\mathcal{S}\mapsto\mathbb{R}} &= \{ 1 \mapsto x, 2 \mapsto y, 3 \mapsto z \} \\ &\vphantom{\Big|}\phantom{\,}\Updownarrow \\ f_{\mathbb{R}^3} &= \begin{bmatrix}x \\ y \\ z\end{bmatrix} \end{align*}\]
If $$\mathcal{S}$$ is finite, a function from $$\mathcal{S}$$ to a field directly corresponds to a familiar finite-dimensional vector. ↩︎
Earlier, we used countably infinite-dimensional vectors to represent functions on the natural numbers. In doing so, we implicitly employed the standard basis of impulse functions indexed by $$i \in \mathbb{N}$$. Here, we encode real polynomials by choosing new basis functions of type $$\mathbb{R}\mapsto\mathbb{R}$$, namely $$\mathbf{e}_i[x] = x^i$$. ↩︎
Since this basis spans the space of analytic functions, analytic functions have countably infinite dimensionality. Relative to the uncountably infinite-dimensional space of all real functions, analytic functions are vanishingly rare! ↩︎
Actually, it states that a compact self-adjoint operator on a Hilbert space admits an orthonormal eigenbasis with real eigenvalues. Rigorously defining these terms is beyond the scope of this post, but note that our intuition about “infinite-dimensional matrices” only legitimately applies to this class of operators. ↩︎
Specifically, a basis for the domain of our Laplacian, not all functions. We’ve built up several conditions that restrict our domain to square integrable, periodic, twice-differentiable real functions on $$[0,1]$$. ↩︎
Also known as a vibe check. ↩︎
Higher-dimensional Laplacians are sums of second derivatives, e.g. $$ \Delta f = \frac{\partial^2 f}{\partial x^2} + \frac{\partial^2 f}{\partial y^2} + \frac{\partial^2 f}{\partial z^2} $$. The Laplace-Beltrami operator expresses this sum as the divergence of the gradient, i.e. $$ \Delta f = \nabla \cdot \nabla f $$. Using exterior calculus, we can further generalize divergence and gradient to produce the Laplace-de Rham operator, $$ \Delta f = \delta d f $$, where $$\delta$$ is the codifferential and $$d$$ is the exterior derivative. ↩︎
Typically, a “harmonic” function must satisfy $$\Delta f = 0$$, but in this case we include all eigenfunctions. ↩︎
The associated Legendre polynomials are closely related to the Legendre polynomials, which form an orthogonal basis for polynomials. Interestingly, they can be derived by applying the Gram–Schmidt process to the basis of powers ($$1, x, x^2, \dots$$). ↩︎
{kind=link}