Oxidizing C++
I recently rewrote the C++20 infrastructure I use for personal projects, so I decided to snapshot its design in the style of another recent article. The library (rpp) is primarily inspired by Rust, and may be found on GitHub.
I use rpp as an STL replacement, and I’m currently developing a real-time path tracer with it. rpp attempts to provide the following features, roughly in priority order:
Fast Compilation
Including rpp should not increase compilation time by more than 250ms. It must not pull in any STL or system headers—they’re what’s really slow, not templates.
Debugging
User code should be easy to debug. That requires good debug-build performance, defensive assertions, and prohibiting exceptions/RTTI. Concepts should be used to produce straightforward compilation errors.
Performance
User code should have control over allocations, parallelism, and data layout. This is enabled by a region-based allocator system, a coroutine scheduler, and better default data structure implementations. Additionally, tracing-based profiling and allocation tracking are tightly integrated.
Explicitness
All non-trivial operations should be visible in the source code. That means prohibiting implicit conversions, copies, and allocations, as well as using types with clear ownership semantics.
Metaprogramming
It should be easy to perform compile-time computations and reflect on types. This involves pervasive use of concepts and constexpr, as well as defining a format for reflection metadata.
These goals lead to a few categories of interesting features, which we’ll discuss below.
Standard disclaimers: no, it wouldn’t make sense to enforce this style on existing projects/teams, no, the library is not “production-ready,” and yes, C++ is Bad™ so I considered switching to language X.
Compile Times
Note: this is all pre-modules, so may change soon. CMake recently released support!
C++ compilers are slow, but building your codebase doesn’t have to be. Let’s investigate how MSVC spends its time compiling another project of mine, which is written in a mainstream C++17 style. Including dependencies, it’s about 100k lines of code and takes 20 seconds to compile with optimizations enabled.1
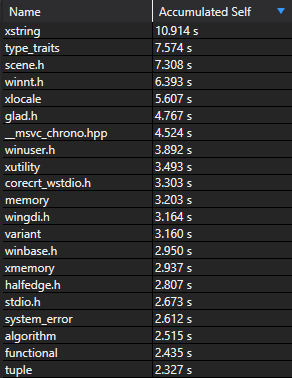
Processing this list of files took up the vast majority of compilation time, but only a handful are actually used in the project—the rest were pulled in to support the STL.
We’ll also find several compilation units that look like this:

Here, including only std::chrono took 75% of the entire invocation.
One would hope that incremental compilation is still fast, but the slowest single compilation unit spent ten seconds in the compiler frontend. Much of that time was spent solving constraints, creating instances, and generating specializations for STL data structures.
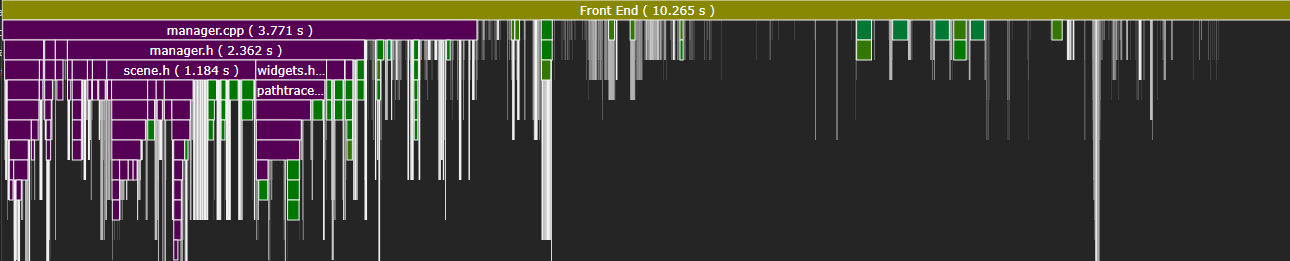
The STL’s long compile times can be mitigated by using precompiled headers (or modules…in C++23), but the core issue is simply that the STL is huge.
So, how fast can we go by avoiding it? Here’s my rendering project, which is also roughly 100k lines of code, including rpp and other dependencies. (Click to play.)
The optimized build completes in under 3 seconds. There’s no trick—I’ve just minimized the amount of code included into each compilation unit. Let’s take a look at where MSVC spends its time:
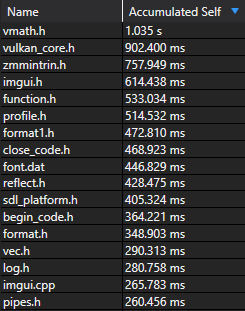
Most of these files come from non-STL dependencies and are actually required by the project. Several arise from rpp, but the worst offender (vmath) only accumulated 1s of work.
Incremental compilation is also much improved: the slowest compilation unit only spent 1.4s in the frontend.
Within each unit, we can see that including base.h (the bulk of rpp) took under 200ms on average.

Of course, this is not a proper benchmark: I’m comparing two entirely separate codebases. Project structure has a large impact on compile times, as does usage code, so your milage may vary. Nevertheless, after working on both projects, I found the decreased iteration time alone to be worth ditching the STL.
How?
You might wonder whether rpp only compiles quickly because it omits most STL features. This is obviously true to some extent: it’s only 10k lines of code, only supports Windows/Linux/x64, and isn’t concerned with backwards compatibility.
However, rpp replicates all of the STL features I actually use.
Implementing the core functionality takes relatively little code, and given some care, we can keep compile times low.
For example, we can still use libc and the Windows/Linux APIs, so long as we relegate their usage to particular compilation unit.2
User code only sees the bare-minimum symbols and types—windows.h need not apply.
OS_Thread sys_start(OS_Thread_Ret (*f)(void*), void* data);
void sys_join(OS_Thread thread);
Unfortunately, the same cannot be said for the STL proper, as (most) generic code must be visible to all compilation units. Hence, rpp re-implements many STL data structures and algorithms. They’re not that hard to compile quickly—STL authors have just never prioritized it.
array.h box.h files.h format.h function.h hash.h heap.h log.h map.h
math.h opt.h pair.h thread.h queue.h rc.h reflect.h rng.h stack.h
string.h tuple.h variant.h vec.h
These two approaches let us entirely eliminate standard headers.
Due to built-in language features, we can’t quite get rid of std::initializer_list and std::coroutine_handle, but the necessary definitions can be manually extracted into a header that does not pull in anything else.
Data Structures and Reflection
Let’s discuss rpp’s primary data structures.
We will write T and A to denote generic type parameters and allocators, respectively.
The following section will discuss allocators in more detail.
Pointers
There are five types of pointers, each with different ownership semantics.
Except for raw pointers, all must point to a valid object or be null.
T*is rarely used. The referenced memory is never owned; there are no other guarantees.Ref<T>is nearly the same as a raw pointer but removes pointer arithmetic and addsnullchecks.Box<T, A>is a uniquely owning pointer, similar tostd::unique_ptr. It may be moved, but not copied, and frees its memory when destroyed.Rc<T, A>is a non-atomically reference-counted pointer. The reference count is stored contiguously with the pointed-to object. It may be moved or copied and frees its memory when the last reference is destroyed.Arc<T, A>is an atomically reference-countedRc, similar tostd::shared_ptr.
Strings
String<A> contains a pointer, a length, and a capacity.
Strings are not null-terminated and may contain null bytes.
There is no “small-string” optimization, so creating a non-empty string always allocates.3
String_View provides a non-owning immutable view of a string, similar to std::string_view.
Most non-destructive string operations are implemented on String_View.
String literals may be converted to String_Views using the _v literal suffix.
String_View message = "foo"_v;
String<> copy = message.string<>();
if(copy.view() == "bar"_v) // ...
Arrays
Array<T, N> is a fixed-size array of length N.
It’s essentially an rpp-compatible std::array.
Array<i32, 3> int_array{0, 1, 2};
Vec<T, A> is a dynamically-sized array, similar to std::vector.
There is no “small-vector” optimization, so creating a non-empty vector always allocates.4
Vec<i32> int_vec{0, 1, 2};
int_vec.push(3);
int_vec.pop();
Slice<T> is a non-owning immutable view of a contiguous array, similar to std::span.
A Slice may be created from an Array, a Vec, a std::initializer_list, or a raw pointer & length.
Non-destructive functions on arrays take Slice parameters, which abstract over the underlying storage.
This erases (e.g.) the size of the Array or the allocator of the Vec, reducing template bloat.
void print_slice(Slice<i32> slice) {
for(i32 i : slice) info("%", i);
}
Stack<T, A>, Queue<T, A>, and Heap<T, A> are array-based containers with stack, queue, and heap semantics, respectively.
Queue is implemented using a growable circular buffer, and Heap is a flat binary min-heap with respect to the less-than operator.
Stack<i32> int_stack{1, 2, 3};
int_stack.top(); // 3
Queue<i32> int_queue{1, 2, 3};
int_queue.front(); // 1
Heap<i32> int_heap{1, 2, 3};
int_heap.top(); // 1
Hash Map
Map<K, V, A> is an open-addressed hash table with Robin Hood linear probing.
For further discussion of why this is a good choice, see Optimizing Open Addressing.
Map<String_View, i32> int_map{Pair{"foo"_v, 0}, Pair{"bar"_v, 1}};
int_map.insert("baz"_v, 2);
int_map.erase("bar"_v);
for(auto& [key, value] : int_map) info("%: %", key, value);
The implementation is very similar to Optimizing Open Addressing, except that the table also stores key hashes. This improves performance when hashing keys is expensive—particularly for strings.5
Optional
Opt<T> is either empty or contains a value of type T.
It is not a pointer; it contains a boolean flag and storage for a T.
Optionals are used for error handling, as rpp does not use exceptions.
Opt<i32> int_opt{1};
if(int_opt) info("%", *int_opt);
There is currently no Result<T, E> type, but I plan to add one.
Tuples
Pair<A, B> contains two values of types A and B.
It supports structured bindings and is used in the implementation of Map.
Pair<i32, f32> pair{1, 2.0f};
i32 one = pair.first;
auto [i, f] = pair;
Tuple<A, B, C, ...> is a heterogeneous product type, which may be accessed via (static) indexing or structured binding.
Tuple<i32, f32, String_View> product{1, 2.0f, "foo"_v};
i32 one = product.get<0>();
auto [i, f, s] = product;
An N-element tuple is represented by a value and an N-1-element tuple. At runtime, this layout is equivalent to a single struct with N fields.
struct { A first; struct { B first; struct { C first; struct {}}}}
The linear structure makes compile-time tuple operations occur in linear time—but I haven’t found this to be an issue in practice. Structuring tuples as binary trees would accelerate compilation, but the code would be more complex.
Variant
Variant<A, B, C, ...> is a heterogeneous sum type.
It is superficially similar to std::variant, but has several important differences:
- It is never default constructable, so there is no
std::monostate. - It cannot be accessed by index or by alternative, so there is no
std::bad_variant_access. - rpp does not use exceptions, so there is no
valueless_by_exception. - The alternatives do not have to be destructible.
- The alternatives must be distinct.
Variants are accessed via (scuffed) pattern matching: the match method invokes a callable object overloaded for each alternative.
The Overload helper lets the user write a list of (potentially polymorphic) lambdas.
Variant<i32, f32, String_View> sum{1};
sum = 2.0f;
sum.match(Overload{
[](i32 i) { info("Int %", i); },
[](f32 f) { info("Float %", f); },
[](auto) { info("Other"); },
});
Requiring distinct types means a variant can’t represent multiple alternatives of the same type.
We can work around this restriction using the Named helper, but the syntax is clunky.
Variant<Named<"X", i32>, Named<"Y", i32>> sum{Named<"X", i32>{1}};
sum.match(Overload{
[](Named<"X", i32> x) { info("%", x.value); },
[](Named<"Y", i32> y) { info("%", y.value); },
});
Like optionals, variants are not pointers: they contain an index and sufficient storage for the largest alternative.
However, variants also need a way to map the runtime index to a compile-time type.
Given at most eight alternatives, it simply checks the index with a chain of if statements.
Otherwise, it indexes a static table of function pointers, which is generated at compile time.
This introduces an indirect call, but is still relatively fast.
Function
Function<R(A, B, C...)> is a type-erased closure.
It must be provided parameters of types A, B, C, etc., and returns a value of type R.
Function is similar to std::function, but has a few important differences:
- It is not default constructable, so there is no
std::bad_function_call. - It is not copyable (like
std::move_only_function). - The “small function” optimization is required: constructing a function never allocates.
Functions can be constructed from any callable object with the proper type—in practice, usually a lambda.
Function<void(i32)> print_int = [](i32 i) { info("%", i); };
By default, a Function only has 4 words of storage, so there’s also FunctionN<N, R(A, B, C...)>, which has N words of storage.
In-place storage implies that all functions in a homogeneous collection must have a worst-case size.
If this becomes a problem, you should typically defunctionalize or otherwise restructure your code.
At runtime, functions contain an explicit vtable pointer and storage for the callable object. The vtable is a static array of function pointers generated at compile time. Calling, moving, or destroying the function requires an indirect call—where possible, it’s better to template usage code on the underlying function type.
Explicitness
In rpp, all non-trivial operations should be visible in the source code. This is not generally the case in mainstream C++: most types can be implicitly copied, single-argument constructors introduce implicit conversions, and many operations conditionally allocate memory.
Copies
Unlike the STL, rpp data structures cannot be implicitly copied.
To duplicate (most) non-trivial types, you must explicitly call their clone method.
Vec<i32> foo{0, 1, 2};
Vec<i32> bar = foo.clone();
Vec<i32> baz = move(foo);
The Clone concept expresses this capability, allowing generic code to clone supported types.
Additionally, concepts are used to pick the most efficient implementation of clone.
For example, “trivially copyable” types can be copied with memcpy, as seen in Array:
Array clone() const
requires(Clone<T> || Copy_Constructable<T>) {
Array result;
if constexpr(Trivially_Copyable<T>) {
Libc::memcpy(result.data_, data_, sizeof(T) * N);
} else if constexpr(Clone<T>) {
for(u64 i = 0; i < N; i++) result[i] = data_[i].clone();
} else {
for(u64 i = 0; i < N; i++) result[i] = T{data_[i]};
}
return result;
}
Constructors
Roughly all constructors are marked as explicit, so do not introduce implicit conversions.
I think this is the correct tradeoff, but it has a downside: type inference for template parameters is quite limited.
That means we often have to annotate otherwise-obvious types.
Vec<i32> make_vec(i32 i) {
return Vec<i32>{i}; // Have to write the "<i32>"
}
Reflection
Compared to previous versions, C++20 has much better native support for compile-time computation.
Hence, rpp does not provide many metaprogramming tools beyond using constexpr, consteval, etc. where possible.
However, it does include a reflection system, which is used to implement a generic printf.
To make a type reflectable, the user creates a specialization of the struct Reflect::Refl.
This may be done manually, or with a helper macro. For example:
struct Data {
Vec<i32> ints;
Vec<f32> floats;
};
RPP_RECORD(Data, RPP_FIELD(ints), RPP_FIELD(floats));
By default, rpp provides specializations for all built-in types and rpp data structures. Eventually, we’ll get proper compiler support for reflection, but it’s still years away from being widely available.6
The generated reflection data enables operating on types at compile time. For example, we can iterate the fields of an arbitrary record:
struct Print_Field {
template<Reflectable T>
void apply(const Literal& field_name, const T& field_value) {
info("%: %", field_name, field_value);
}
};
Data data;
iterate_record(Print_Field{}, data);
The reflection API includes various other low-level utilities, but it’s largely up to the user to build higher-level abstractions. One example is included: a generic printing system, which is used in the logging macros we’ve seen so far.
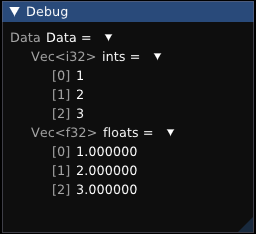
Data data{Vec<i32>{1, 2, 3}, Vec<f32>{1.0f, 2.0f, 3.0f}};
info("%", data);
By default, formatting a record will print each field.
Formatting behavior can be customized by specializing Format::Write / Format::Measure, which are provided for all built-in data structures.
Data{ints : Vec[1, 2, 3], floats : Vec[1.000000, 2.000000, 3.000000]}
The implementation is surprisingly concise: it’s essentially an if constexpr branch for each primitive type, plus iterating records/enums.
It’s also easy to extend: for my renderer, I wrote a similar system that generates Dear ImGui layouts for arbitrary types.
Allocators, Regions, and Tracing
In rpp, all data structures are statically associated with an allocator.
Vec<u64, Mdefault> vector;
This approach appears similar to the STL, which also parameterizes data structures over allocators, but is fundamentally different. An rpp allocator is purely a type, not a value, so is fully determined at compile time. That means the specific allocator used by a data structure is part of its type.
By default, all allocations come from Mdefault, which is a thin wrapper around malloc/free that records allocation events.
It starts to get interesting once we allow the user to define new allocators:
using Custom = Mallocator<"Custom">;
Vec<u64, Custom> vector;
Here, Custom still just wraps malloc/free, but its allocation events are tracked under a different name.
Now, if we print allocation statistics:
Allocation stats for [Custom]:
Allocs: 3
Frees: 3
High water: 8192
Alloc size: 24576
Free size: 24576
Printing this data at program exit makes it easy to find memory leaks and provides a high-level overview of where your memory is going.
Regions
Tracking heap allocations is useful, but it doesn’t obviously justify the added complexity. More interestingly, rpp data structures also support stack allocation. The rpp stack allocator is a global, thread-local, chunked buffer that is used to implement regions. For further discussion of this design, see Oxidizing OCaml.
Passing the Mregion allocator to a data structure causes it to allocate from the current region.
Allocating region memory is almost free, as it simply bumps the stack pointer.
Freeing memory is a no-op.
Vec<u64, Mregion<R>> local_vector;
Regions are denoted by the Region macro.
Each region lasts until the end of the following scope, at which point all associated allocations are freed.
Region(R) { // R starts here
// Allocate a Vec in R
Vec<u64, Mregion<R>> local_vector;
local_vector.push(1);
local_vector.push(2);
} // R ends here
Unfortunately, regions introduce a new class of memory bugs. Region-local values must not escape their scope, and a region must not attempt to allocate memory associated with a parent. In OCaml or Rust, these properties can be checked at compile time, but not so in C++.
Instead, rpp uses a runtime check to ensure region safety.
When allocating or freeing memory, the allocator checks that the current region has the same brand as the region associated with the allocation.
Brands are named by the user and passed as the template parameter of Mregion.
Region(R0) {
Vec<u64, Mregion<R0>> local_vector;
Region(R1) {
local_vector.push(1); // Region brand mismatch!
}
}
Brands are compile-time constants derived from the region’s source location, so do not introduce any runtime overhead beyond the check itself.
Since C++17, the STL also supports allocator polymorphism—that is, runtime polymorphism.
For example, std::pmr::monotonic_buffer_resource can be used to implement regions, but it incurs an indirect call for every allocation.
Conversely, rpp’s regions are fully determined at compile time.
This design also sidesteps the problem of nested allocators, which is a major pain point in the STL.
Pools
Most allocations are either very long-lived, so go on the heap, or very short-lived, so go on the stack. However, it’s occasionally useful to have a middle ground, so rpp also provides pool allocators.
A pool is a simple free-list containing fixed-sized blocks of memory. When the pool is not empty, allocations are essentially free, as they simply pop a buffer off the list. Freeing memory is also trivial, as it pushes the buffer back onto the list.
Passing Mpool to a data structure causes it to allocate from the properly sized pool.
Since pools are fixed-size, Mpool can only be used for “scalar” allocations, i.e. Box, Rc, and Arc.
Box<u64, Mpool> pooled_int{1};
Each size of pool gets its own statistics:
Allocation stats for [Pool<8>]:
Allocs: 2
Frees: 2
High water: 16
Alloc size: 16
Free size: 16
Mpool is similar to std::pmr::synchronized_pool_resource, but is much simpler, as it only supports one block size and does not itself coalesce allocations into chunks.
Currently, each pool is globally shared using a mutex.
This is not ideal, but may be improved by adding thread-local pools and a global fallback.
Polymorphism
Parameterizing data structures over allocators provides a lot of flexibility—but it makes all of their operations polymorphic, too.
Regions exacerbate the issue: for example, a function returning a locally-allocated Vec must be polymorphic over all regions.
template<Region R>
Vec<i32, Mregion<R>> make_local_vec() {
return Vec<i32, Mregion<R>>{1, 2, 3};
}
The same friction is present in Rust, where references give rise to lifetime polymorphism. (In fact, brands are a restricted form of lifetimes.) The downside of this approach is code bloat. Due to link-time deduplication, I haven’t run into any issues with binary size, but it could become a problem in larger projects.
Tracing
In addition to tracking allocator statistics, rpp records a list of allocation events for each frame.7 This data makes it easy to target an average of zero heap allocations per frame—other than growing the stack allocator.
Furthermore, rpp includes a basic tracing profiler.
To record how long a block of code takes to execute, simply wrap it in Trace:
Trace("Trace Me") {
// ...
}
The profiler will compute how many times the block was entered, how much time was spent in the block, and how much time was spent in the block’s children. The resulting timing tree can be traversed by user code, but rpp does not otherwise provide a UI.
In my renderer, I’ve used rpp’s profile data to graph frame times (based on LegitProfiler):
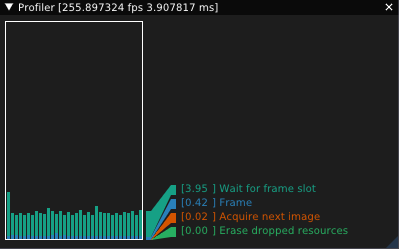
Finally, note that tracing is disabled in release builds.
Coroutines
Coroutines were a somewhat controversial addition to C++20, but I’ve found them to be a good fit for rpp.
Creating an rpp task involves returning an Async::Task<T> from a coroutine:
Async::Task<i32> task1() {
co_return 1;
};
To execute a task on another thread, simply create a thread pool and await pool.suspend().
When a coroutine awaits another task, it will be suspended until the completion of the awaited task.
Async::Task<i32> task2(Async::Pool<>& pool) {
co_await pool.suspend();
co_return co_await task1();
};
It’s possible to write your entire program in terms of coroutines, but it’s often more convenient to maintain a main thread. Therefore, tasks also support synchronous waits:
Async::Pool<> pool;
auto task = task2(pool);
info("%", task.block());
Tasks may be awaited at most once, cannot be copied, and cannot be cancelled after being scheduled.8 These limitations allow the implementation to be quite efficient:
- Tasks are just pointers to coroutine frames.
- Promises add minimal additional state: a status word, a flag for synchronous waits, and the result value.
- Executing a coroutine only allocates a single object (the frame).
Notably, managing the promise lifetime doesn’t require reference counting. Instead, rpp uses a state machine based on Raymond Chen’s design.
| Task is... | Old Promise State | New Promise State | Action |
|---|---|---|---|
| Created | Start | ||
| Awaited | Done | Done | Resume Awaiter |
| Awaited | Start | Awaiter Address | Suspend Awaiter |
| Completed | Start | Done | |
| Completed | Abandoned | Destroy | |
| Completed | Awaiter Address | Done | Resume Awaiter |
| Dropped | Start | Abandoned | |
| Dropped | Done | Destroy |
Since the awaiter’s address can’t be zero (Start) one (Done) or two (Abandoned), we can encode all states in a single word and perform each transition with a single atomic operation. Additionally, we can use symmetric transfer to resume tasks without requeuing them.
Currently, the scheduler does not support work stealing, prioritization, or CPU affinity, so blocking on another task can deadlock. I plan to add support for these features in the future.
Asynchronous I/O
As seen in many other languages, coroutines are also useful for asynchronous I/O. Therefore, the rpp scheduler supports awaiting platform-specific events. Its design is roughly based on coop.
Only basic support for async file I/O and timers is included, but creating custom I/O methods is easy:
Task<IO> async_io(Pool<>& pool) {
HANDLE handle = /* Start an IO operation */;
co_await pool.event(Event::of_sys(handle));
co_return /* The result */;
}
In my renderer, this system enables awaitable GPU tasks based on VK_KHR_external_fences.
co_await vk.async(pool, [](Vk::Commands& commands) {
// Add GPU work to the command buffer
});
Compiler Bugs
Despite compilers having supported coroutines for several years, I still ran into multiple compiler bugs while implementing rpp. This suggests that coroutines are still not widely used, or I imagine the bugs would have been fixed by now.
In particular, MSVC 19.37 exhibits a bug that makes symmetric transfer unsafe, so it’s currently possible for the rpp scheduler to stack overflow on Windows.
As of Jan 2024, a fix is pending release by Microsoft.
I ran into a similar bug in clang, but didn’t track it down precisely because updating to clang-17 fixed the issue.
Appendix: why not language X?
This may seem like a lot of work that would be better spent transitioning to Rust. Much of rpp is directly inspired by Rust—even the name—but I haven’t been convinced to switch just yet. The kind of projects I work on (i.e. graphics & games) tend to be both borrow-checker-unfriendly and do not primarily suffer from memory or concurrency issues.
That’s not to say these kind of bugs never come up, but I find debuggers, sanitizers, and profiling sufficient to fix issues and prevent regressions. I would certainly prefer these bugs to be caught at compile time, but I haven’t found the language overhead of Rust to be obviously worth it—the painful bugs come from GPU code anyway! Of course, it might be a different story if I wrote security-critical programs.
What has really held me back is simply that the Rust compiler is slow—but now that the parallel frontend has landed, I may reconsider. I would also concede that Rust is the better language to start learning in 2024.
Jai prioritizes many of the same goals as rpp. I sure would like to use it, but it’s been nine years and I still don’t have a copy of the compiler.
In the past, I’ve written a lot of C-style C++, including the first version of rpp (unnamed at the time). In retrospect, I don’t think this style is a great choice, unless you’re very disciplined about not using C++ features. Introducing even a small amount of C++isms leads to a lot of poor interactions with C-style code. Overall, I’d say it’s better to return to plain C.
That said, rpp is obviously influenced by this style: it doesn’t use exceptions, RTTI, multiple/virtual inheritance, or the STL. However, it does make heavy use of templates.
C
I’ve also written a fair amount of C, and I’d say it’s still a good choice for OS-adjacent work. However, I rarely need to think about topics like binary size, inline assembly, or ABI compatibility, so I’d rather have (e.g.) real language support for generics. Plus, at least where available, Rust is often a better choice.
I haven’t written much D, but from what I’ve seen, it’s a pretty sensible redesign of C++. Many of the features that interact poorly in C++ work well in D. However, there’s also the garbage collector—it can be disabled, but you lose out on a lot of library features. Overall, I think D suffers from the problem of being “only” moderately better than C++, which isn’t enough to justify rebuilding the ecosystem.
I tried Odin in 2017, but it wasn’t sufficiently stable at the time. It appears to be in a good state today—and certainly improves on C for application programming—but I think it suffers from the same problem that D does relative to C++.
I feel obligated to mention OCaml, since I now use it professionally, even for systems programming tasks. Modes, unboxed types, and domains are starting to make OCaml very viable for systems-with-incremental-concurrent-generational-GC projects—but it’s not yet a great fit for games/graphics programming.
I would particularly like to see an ML-family language without a GC (maybe along the lines of Koka), but not so imperative/object oriented as Rust.
Zig, Nim, Go, C#, F#, Haskell, Beef, Vale, Java, JavaScript, Python, Crystal, Lisp
I’ve learned about each these languages to some small extent, but none seem sufficiently compelling for my use cases. (Except maybe Zig, which scares me.)
Footnotes
The 100k LOC do not include the STL itself. Benchmarked on an AMD 5950X @ 4.4GHz, MSVC 19.38.33129, Windows 11 10.0.22631. ↩︎
Unfortunately, this makes the implementations unavailable for inlining. However, I’m prioritizing compile times, and link-time optimization can make up for it. ↩︎
Adding the small-string optimization only makes sense if it happens to accelerate an existing codebase. It causes strings’ allocation behavior to depend on their length, resulting in less predictable performance. Further, if your program creates a lot of small, heap-allocated
String<>s, you should ideally refactor it to useString_View, the stack allocator, or a custom interned string representation. ↩︎(For the same reasons as strings.) ↩︎
It also stores hashes alongside integer keys, which doesn’t help. I’ll fix this eventually. ↩︎
Of course, this data could be generated by a separate meta-program or a compiler plugin, but I haven’t found the additional complexity to be worth it. ↩︎
Assuming your program is long-running and has a natural frame delineation. Otherwise, the entire execution is traced under one frame. ↩︎
Because tasks may only be awaited once, they do not support
co_yield. ↩︎